Sport Agnostic Data Modeling
A summary Of Rethink Your Master Data (MDM)
Introduction
Data is both our most valuable asset and our biggest ongoing challenge. As data grows volume, variety, and complexity, across applications, clouds, and soiled systems, traditional ways of working with data no longer work. Increasingly, we are recognizing a need to harness all of our data, particularly our data around matches, players, lineups, teams, and more - often called master data. Pressing business priorities such as data transformations and aggregations require a holistic view of this master data.
A Big Data Problem
-
Many organization have lots of data, but it's soiled and disconnected. Data is spread across:
- - Different teams like (Different isolated systems - User analytics - Analysis databases)
- - Different platforms (Web browser - Desktop apps - Mobile apps)
- - Different formats (Database Schema - Object based - No SQL - Kafka Data Format, Avro - Data sheets)
- - Different locations (cloud - on-prem)
without a holistic view of our data, fragmentation, misunderstandings, inaccuracies and mistakes abound. Worse, disconnected data creates friction that makes querying more difficult. Aggregations between different teams is hard to be achievable.
Modern Master Data Management
Currently, having MDM systems requires centralized approaches. Such systems use a rigid schema of changes and additions and always in silos without any proper relations or linking.
Graph Technology?
Graph database technology offers a proven way to connect master data. It enables you to start right where you are with a use case that solves pressing problems and creates immediate business value. It gives you the flexibility to connect data across existing MDM systems or use the graph data store itself as an MDM system. Graph databases give you the advantage of understanding networks and connections of data. Unlike relational databases with grid-like structures that are not optimized for traversing relations. Despite the name 😕. It cannot handle connected information, so querying data relationships require numerous *SQL JOINS.*
The Power of Graph Technology
Graph queries are fast and easy to have natural connections hidden in data and scale perfectly with the ability of querying millions of records within very few seconds. Ten times faster than normal querying in a relational database. Advantages:
-
- Support for any query.
-
- Lightning fast, no matter number of hops
-
- Simple query language (Cypher as for Neo4j)
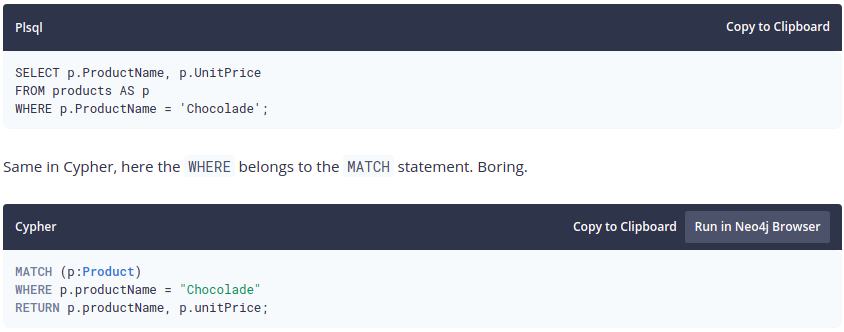
An example showing the difference between querying a product by name using SQL & Cypher:
-
- Complements existing systems, no need to rip and replace anything.
-
- AI/ML on connected data using graph algorithms.
-
- Visualization (whiteboard style structure).
So What Is Really Neo4j Introduces
Neo4j is the most used graph database. Hundreds of companies like [Nasa, Airbnb, UBS, Convergys, Pitney Bowes]. Relations between data are as important as the data itself. Graph databases can traverse huge chunks of data with their connections very effectively and fast. We maintain multiple data sources. In most cases, it's not feasible to move all data into a single data store to query relations. A Neo4j powerful solution can be layerd atop legacy systems and data stores, work across silos, provide a consistent source of information and reveal the relationships hidden.
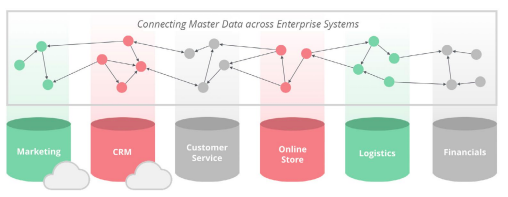
To see real examples of how big companies like Airbnb and Nasa approach different relational problems with Neo4j, please go check the official Neo4j documentation of this summary here [8 mins read].
How We Can Use MDM
- - We can use MDM pattern to connect multiple data sources together to track data changes and transformations across different formats/teams/relations.
- - As for data gathering data scope it can be used to gather all the information being scrapped from different sources together in one data lake.
- - It will make a good fit in the client gateway to list aggregates of every internal data source.